Profiling Performance Monitoring Events for STING's Test Stimulus on Qualcomm Dragonboard 410C
On successfully enabling STING on Qualcomm Dragonboard 410C board, the quality of test stimulus generated by STING was evaluated by profiling the performance monitoring events available in the CPU implementation. As part of this exercise, few open source benchmarks were also profiled for the same set of events and the results were compared with the STING tests to determine the effectiveness of test stimulus.
In this blog, all the steps involved in this activity are recorded. A small subset of the profiling results for a couple of performance monitoring events can be found towards the end of this blog.
Overview of Performance Monitor Unit (PMU) Architecture
ARM CPU implementations include a non-invasisve performance monitoring component based on Performance Monitors Unit (PMU) architecture. The ARMv8 implementations include PMUv3 implementation. At a high level, the PMU implementation defines a set of system registers and a programming specification which can be used by OS/system software to select a group of performance monitoring events and control starting, stopping and recording of the associated counters. One of our previous blogs explains how the programming can be done.
Profiling the Performance Monitoring Events
In order to profile the performance monitoring events, certain changes need to be done in the code flow. The PMU needs to be setup before the code section that needs to be profiled is executed. In addition to that, we need to start and stop the recording of performance monitoring unit events around the code section which needs to be profiled.
...
setup_perf_mon_unit();
...
...
start_perf_mon_unit();
code_section();
stop_perf_mon_unit();
...
In case of STING, the code section profiled was the stimulus generated by its constrained random test generators. The difference in the starting and ending values of the monitored performance events were accumulated over a large number of test iterations and a mean value was computed. In order to do a comparative analysis, few open source benchmarks were ported to STING’s C++-based API framework and same set of performance events were profiled for them over a duration of time.
This blog presents the results from execution of one of the open source benchmarks. The open source benchmark used for the analysis in this blog is known as RAMspeed. It is a cache and memory benchmarking tool. An excerpt from the homepage is pasted below.
... In general, there are *mark benchmarks such as INTmark, FLOATmark, MMXmark and SSEmark. They operate with linear (sequential) data streams passed through ALU, FPU, MMX and SSE units respectively. They allocate certain memory space and start either writing to or reading from it using continuous blocks sized in power of 2 from 1Kb up to the array boundary. This simple algorithm allows to show how fast are both cache and memory subsystems. There are also *mem benchmarks such as INTmem, FLOATmem, MMXmem and SSEmem. These are supposed to illustrate how fast is actual read\write memory performance. Each of them includes four subtests called Copy, Scale, Add and Triad. They're synthetic simulations, but correlate with many real world applications. ...
Only the integer and floating point components of RAMspeed were used for this exercise. In order to make sure that similar traffic patterns were being compared, the tests generated by STING also consisted of load/store operations acting on linear data streams. Also, the code sections for RAMspeed and STING were of different length. Hence, the values recorded for every event were normalized for 1 million CPU cycles.
The next section consists of the profiling results of few performance monitoring events enabled on Qualcomm Dragonboard 410C for the STING tests and the RAMspeed benchmark.
Comparative Results from Event Profiling
The performance monitoring event values from the execution of STING tests and RAMspeed benchmark will be presented in this section. As mentioned earlier, data related to only a few events from 20 tests comprising of 1000 test iterations are given here.
The first event being presented here is on the load/store density of the instruction stream being generated. It is a combinational function of the following architectural events - loads retired, stores retired and instruction retired. Since the tests comprises of consecutive data accesses on linear memory, this event will give an indication of how tight or compact the traffic sequence is.
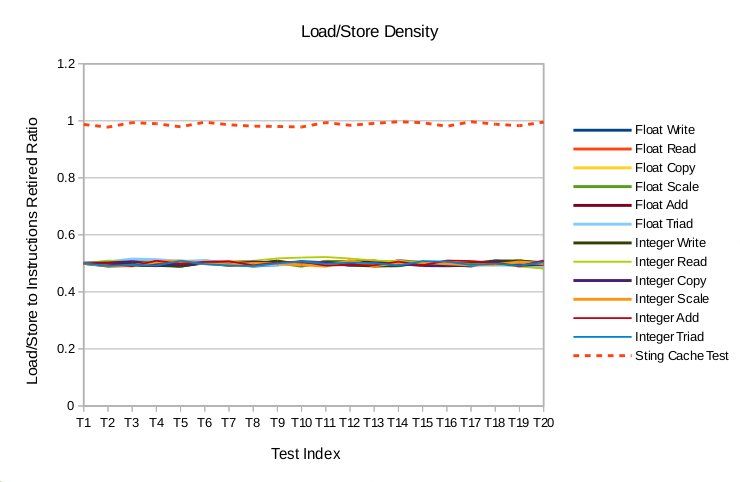
In an ideal scenario, all the instructions run are expected to be loads/stores resulting into a ratio of 1. But the instruction stream generated from the compilation of a C/C++ test (similar to RAMspeed) has lot of other supporting instructions which tends to dilute the test intent. On other hand, the STING tests generate a ratio which is very close to the ideal.
The next table presents the counts for L2 data cache access event. The counter counts memory-read or memory-write operations, that the CPU made, that access at least the level 2 data or unified cache. Each access to a cache line is counted including refills of and write-backs from the level 1 data, instruction, or unified caches. Each access to other level 2 data or unified memory structures, such as refill buffers, write buffers, and write-back buffers, is also counted.
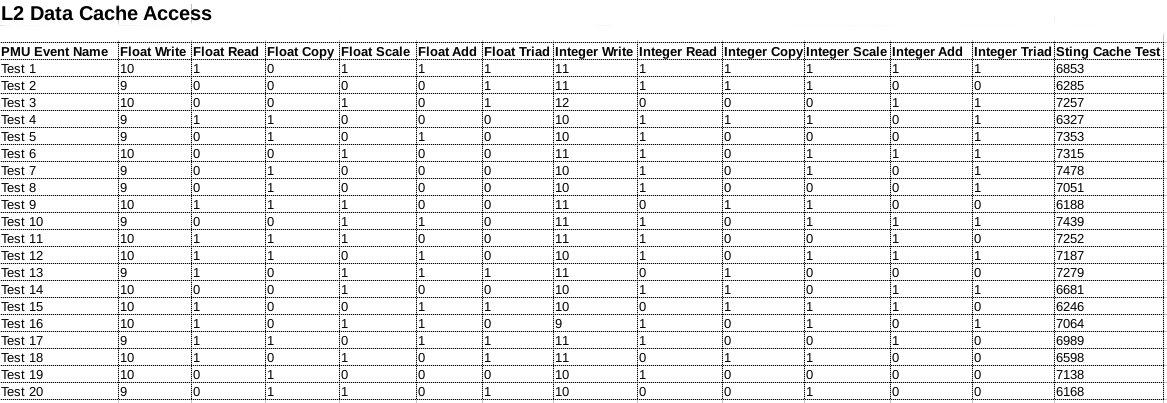
As mentioned earlier, the counts in the table are normalized for 1 million CPU cycles. The high count from STING test can be attributed to the tight sequence of operations.
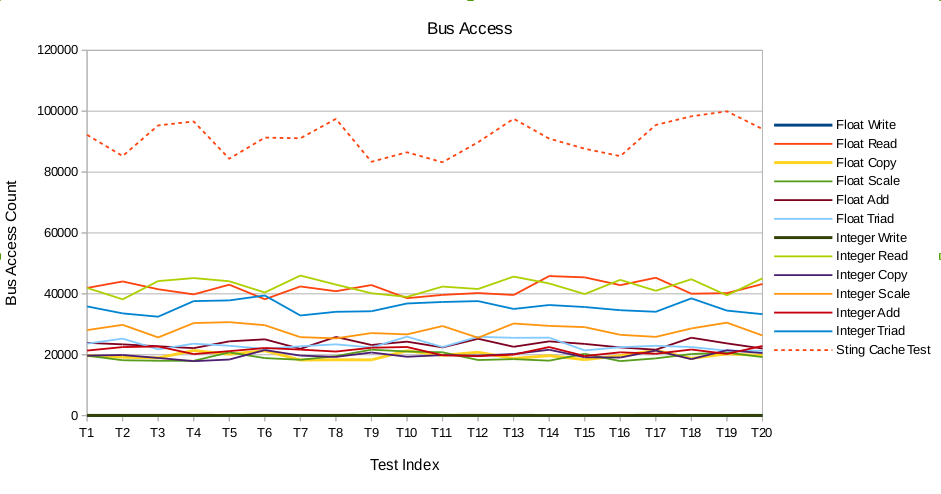
The next event is bus access. The counter increments for evey bus cycle for which the bus is active. It is clear from the diagram that the bus remains active for a longer duration during the STING tests as compared to the benchmark.
Conclusion
The quality of the test stimulus generated by STING can be assessed to some extent by analyzing the profiling results. It is clear that the code sequences generated by STING are very tight. As a result the intent of the test is met in shorted possible time duration. Also, the configuration parameters for biasing of tests can generate any traffic pattern making it an ideal platform for generation of functional stimulus.
Feel free to contact us if you have any questions. The detailed report on all the enabled performance monitoring events and other benchmarks can be shared with interested readers.
Categories: reports
Subscribe
Subscribe to this blog via RSS.
Categories
General 5
Reports 1
Recent Posts
Importance of Software Driven Functional Verification Methodology
Posted on 05 Sep 2020Using STING Release Packages for Verifying RISC-V Implementations
Posted on 25 Oct 2019